2021 年的 Defcon 终于落下了帷幕,想到 2021 年到现在都还没有更新 blog,之前队内一直年更游记的”史官” maskray 教授也 “退休” 了,想着还是得有人记录一下队伍的参赛历程。
本次比赛是我作为 Tea Deliverers 成员参加的第 5 届 Defcon CTF 比赛,同时也是主办方 Order Of the Overflow 在位的最后一届 Defcon 了,在全球疫情肆虐的大环境下,不知道这块 CTF 界的金字招牌未来将会往何处去……
序章:有备而来
初赛结束之后,队长 kelwin 很快召集一些负责统筹的成员开始了决赛的准备工作。
今年除了 TD 去年的老阵容外,加入了长亭的新人 SuperFashi, nan chen 等,还请到了 NeSE 的几位主力选手(afang5472, V1me, kjdy 等)前来参加,实力又进一步增强。
鉴于主办方 OOO 每年的出题人、出题风格都比较固定,kelwin 决定在赛前组织大家进行一下训练和工具准备,以便更好地应对即将到来的决赛。队员们根据技能点的不同被分成 bin 组,koh(King Of the Hill) 组和运维支持组(web 的同学被迫运维),bin 组的同学挑选了一些往年的 challenge 进行逆向、利用的练习,积累经验。运维支持组的同学根据主办方往年提供的记录比赛状态的 json 文件完成一些可视化的工作,以及开发可以自动运行 exploit 的平台。
另外,从往年经验来看,我们的防御方面协作不是很好,往往一个题找到了漏洞之后大家都在调试写利用,而迟迟没有人去 patch. 于是决定今年成立一个 patch 小组,由我来负责,职责是及时跟进每个题目的逆向情况以及是否被 exploit,确保能够及时有人去 patch 漏洞,同时也希望对 patch 进行统一的管理,避免版本过多造成混乱。
不太友好的时间
在今年的特殊条件下,Defcon 仍然选择了在 Las Vegas 的 Paris 和 Bally 酒店现场举行,CTF 的主办方 OOO 则选择了 hybrid 模式,为队伍提供了线下和线上两种参赛的方式。那么自然而然地,比赛时间也就遵循了 Las Vegas 的时间
- Fri, Aug 6, 10am-8pm, set up begins at 9am
- Sat, Aug 7, 10am-8pm, set up begins at 9am
- Sun, Aug 8, 10am-2pm, set up begins at 9am
转换到北京时间
- 8.7 1am-11am,0am 开始配置网络
- 8.8 1am-11am,0am 开始配置网络
- 8.9 1am-5am,0am 开始配置网络
这个作息对于亚洲时区的选手来说可以说相当 “阴间” 了(夜猫子们除外),下文记述不做特别说明都是北京时间。
从前几年的情况看,由于做题人数有限,而且同一个时间段 active 的题目不会很多,往往出现大家前 2 天都怼在同一道题目上重复消耗大量精力的情况,导致在比赛后期放出的一些相对简单的题目没有同学去做。为了避免这种情况再次发生,我们决定将人员分为 3 波,分别应对 8.7 凌晨,8.7 白天,8.8 凌晨的时间,确保在每个时段都有精力充沛的队员能够 work 在新出的 challenge 上,包括”作业”(round 结尾放出的给大家回去做的题)。
赛制介绍
详细赛制可以看官方说明 dc-ctf-2021-finals ,对赛制很熟悉的看官可以跳过这一节。
比赛的轮次叫做 tick,正常为 5 min / tick.
每支队伍的总分由 Attack,Defense 和 KoH 组成,比重分别是 35%, 35% 和 30%. 每个分项会根据所有队伍分数进行归一化,三项的第一名分别是 350, 350 和 300 分,也就是说如果一支队伍三个分项都是第一,总分是 1000 分。
具体到每个分项,attack 是攻击分数,每提交 1 个 flag 获得 1 分。值得注意的是除了正常题目端口,还提供 stealth port,从这个 port 打出的流量不会提供给 victim 队伍,可以用来防止重放,但如果这个 tick 给 stealth port 发了流量,则获得的分数减半,即 1 个 flag 0.5 分。
Defense 为防御分数,每个服务在每个 tick 可以上传一个 patch,如果通过检查则会 deploy,与国内的 CTF 比赛不同的是,deploy 完成的 patch 不会再持续进行 SLA check,所以只需要通过上传时候的检查就可以。如果该 tick 有队伍被打而你的队伍没有被打,则获得 1 分。
KoH 每轮会根据题目不同计算一个排行榜,排名前 5 的队伍将分别获得 10, 6, 3, 2, 1 分,其他队伍不得分。
Day 0:集结号令
本来的计划是所有国内队员全部前往北京长亭总部集结,因为线下交流相对来说方便一些也更为高效。
然而没想到 8 月初北京疫情突然紧张,进京的航班被大面积取消,而且需要核酸检测报告,导致在杭州、上海的队员甚至无法前往北京。除此之外,清华的校园管控也很快升级,学生出校变得极其困难,甚至队长 kelwin 都被隔离在家。无奈只好改为线上会议的形式,设置上海长亭的分基地(libmaru, iromise, gwynbleidd, shyoshyo)和清华实验室的分基地(cxm, ziiiro, s0ght 等),以视频连线的形式进行交流。其他没法去基地的同学(f1yyy, gml 等)也线上接入。
8.6 11:00pm,北京这边的同学陆续抵达了长亭,我在调试好硬件设备(接显示器键盘)后,准备看一会题目再回酒店休息。因为根据安排,我属于做“作业”的那一拨,8.6 晚上需要好好休息,8.7 早起应对新放出的题。不过我还是选择留在现场等比赛开始,因为注定一开始会有些状况发生,在现场还可以帮个忙。
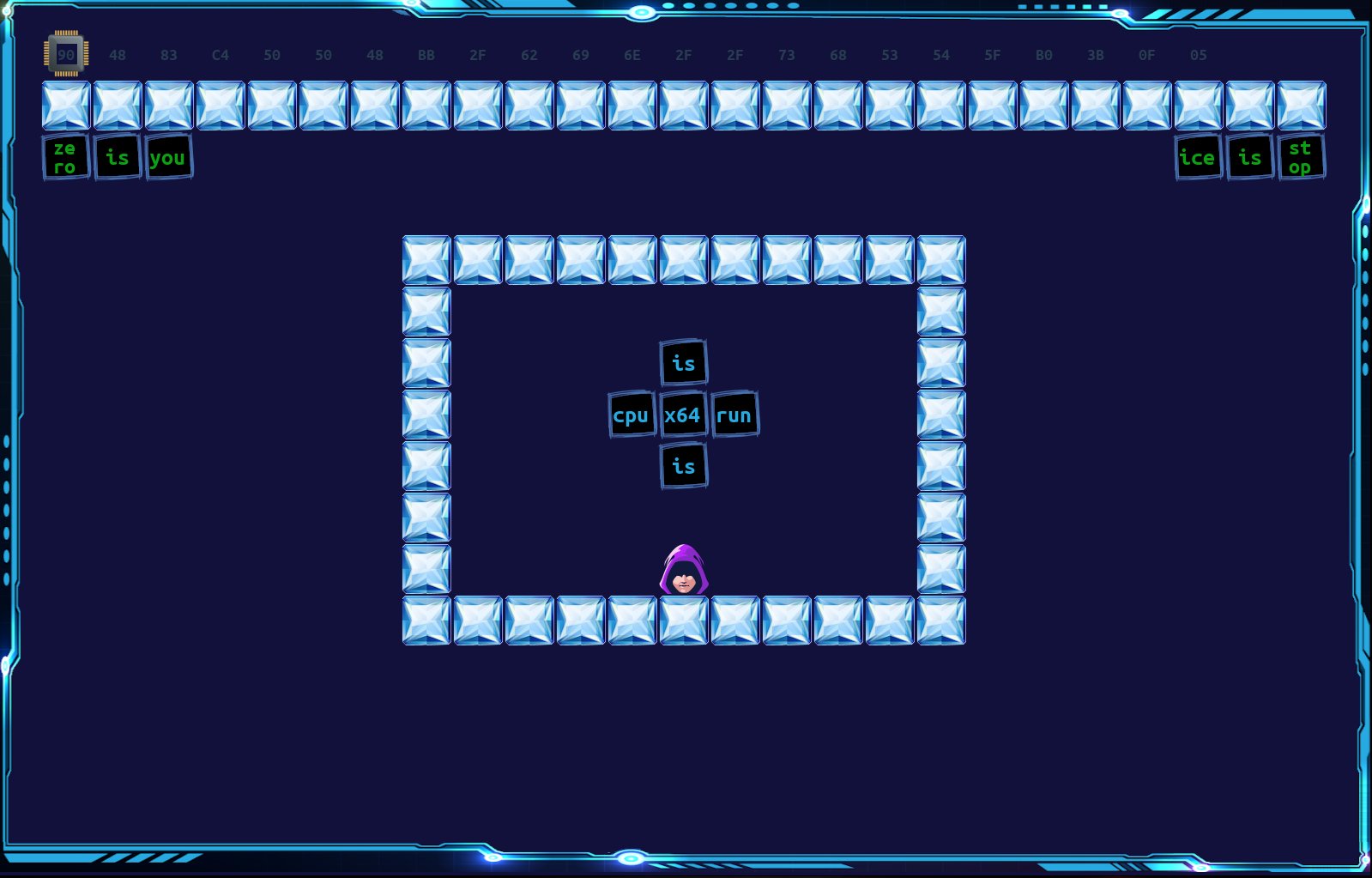
8.7 0:00am,开始配置网络。主办方下发了 jumpbox 的 ssh key,通过 jumpbox 连到比赛网络中,cbmixx 配置好了 VPN 让大家接入。1:00am,比赛平台开启,但是非常卡,众人只加载出来一道 KoH —— zero-is-you,这是受 steam 上的 Baba is You 这款游戏的启发开发的一个小游戏,看样子是需要大家进行闯关。过了一会主办方说遇到了网络问题,暂时推迟到了 2:00am 开始,由于没有其他题目,众人就都研究起了这道 KoH 来.
Day 1:石破天惊
主办方的传统艺能
约莫过了 10 分钟左右,正在研究比赛状态 json 解析的 zTrix 突然说,“主办方题目泄露了”. 众人都是一脸懵,原来是在 game state json 的尾部有一些题目的描述信息和下载地址,似乎是之前测试平台时留下的数据,mcfx 迅速爬取了所有题目描述和题目附件,发现全部都是 AWD 的 challenge. 很快平台就无法访问了,json 也下载不到了,但我们估计应该还有其他队伍也发现了这个问题。这样一来就不存在什么分拨和放题顺序的问题了,而我也被迫留下来分析泄露出的 binary.
泄露出的题目总共有 8 个
- barb-metal:一个运行在 bare x86 上的 iot 服务
- ooopf:似乎跟深度学习有关
- cooorling:奇怪的题目,最后也没放出来
- ooows-*:占了题目的一大部分,是一个系列的 5 个题目,模拟了一个云服务,用户可以上传镜像并在 guest 环境运行。
竟然以这种方式开场,这是我们谁也没有想到的,不知道主办方会怎么处理这个问题,亦或是他们根本就没发现?
不坏的开局
1:48am 左右,Zardus 在 discord 上公开了之前的 json 文件,说 PPP 告诉了他们泄漏的事情,为了公平起见,将 json 发给所有队伍。
2:00am 的 captain meeting 上,发量日渐稀少的 Zardus 告诉众人,将要放出 ooopf 和 barb-metal,但还有题目没有泄露,而且泄露的题目也可能会有所改动(看来主办方准备现场改题)
于是上海的同志们分析起 ooopf,这题的情况我不是特别了解,也不再过多说明题目内容了。
4:00am ooows-flag-baby 放出,同时 StarBugs 一血了 ooopf.
我们这边则开始做 barb-metal,是一个接在 bootloader 之后的内核态 elf,功能是用 mrubyc 读入了一段 ruby 字节码并执行,模拟了一个 iot 设备,可以通过一个菜单读取历史温度数据、播放声音等等。本题的 flag 在初始时候被读入到了一个固定地址,Riatre 迅速找到了一个任意地址读的漏洞,但题目的前端是用 websocket 交互的自动化折腾了一会,随后在 5:00am 一血了这个题目,为了避免重放选择了打 stealth port.
然而一血优势没过多久,6:00am Nu1L 开始打非 stealth port,由于比较好重放,此时场上很多队都开始了攻击,此时防守就显得较为重要了。然而防守端比较麻烦,因为 ruby 字节码在读入的时候对签名进行了校验,待到逆完签名校验逻辑(使用的是 e = 3 的公钥)设计好伪造的方法,补完之后又有了新的 exploit 打过来,刚补好新的洞题目就下线了。总体上看这个题表现差强人意,攻防两端得分都是第 1,但由于很多队伍都能打所以一血的优势不太显著。
5:00am 的时候 shellphish 一血了 ooows-flag-baby,7:00am ooows-flag-baby 下线换成了 ooows-p92021.
11:00am 比赛结束,zero-is-you 下线了,主办方说接下来会放出 ooows-ogx 和 ooows-broadcooom. Zero-is-you 的表现不太乐观,被前面的队伍远远得甩在了后面。不过由于 KoH 只占 30%,我们还是排在了第 4 的位置,前面分别是 PPP, Katzebin 和 StarBugs.
重头戏:ooows
ooows 的服务设计的比较有意思,作为云主题的 5 个服务出起来应该花了不少心思,web 界面上可以让用户上传一个 disk 镜像运行,并看到其 serial / vga 的输出
其内部的大致架构如下图所示
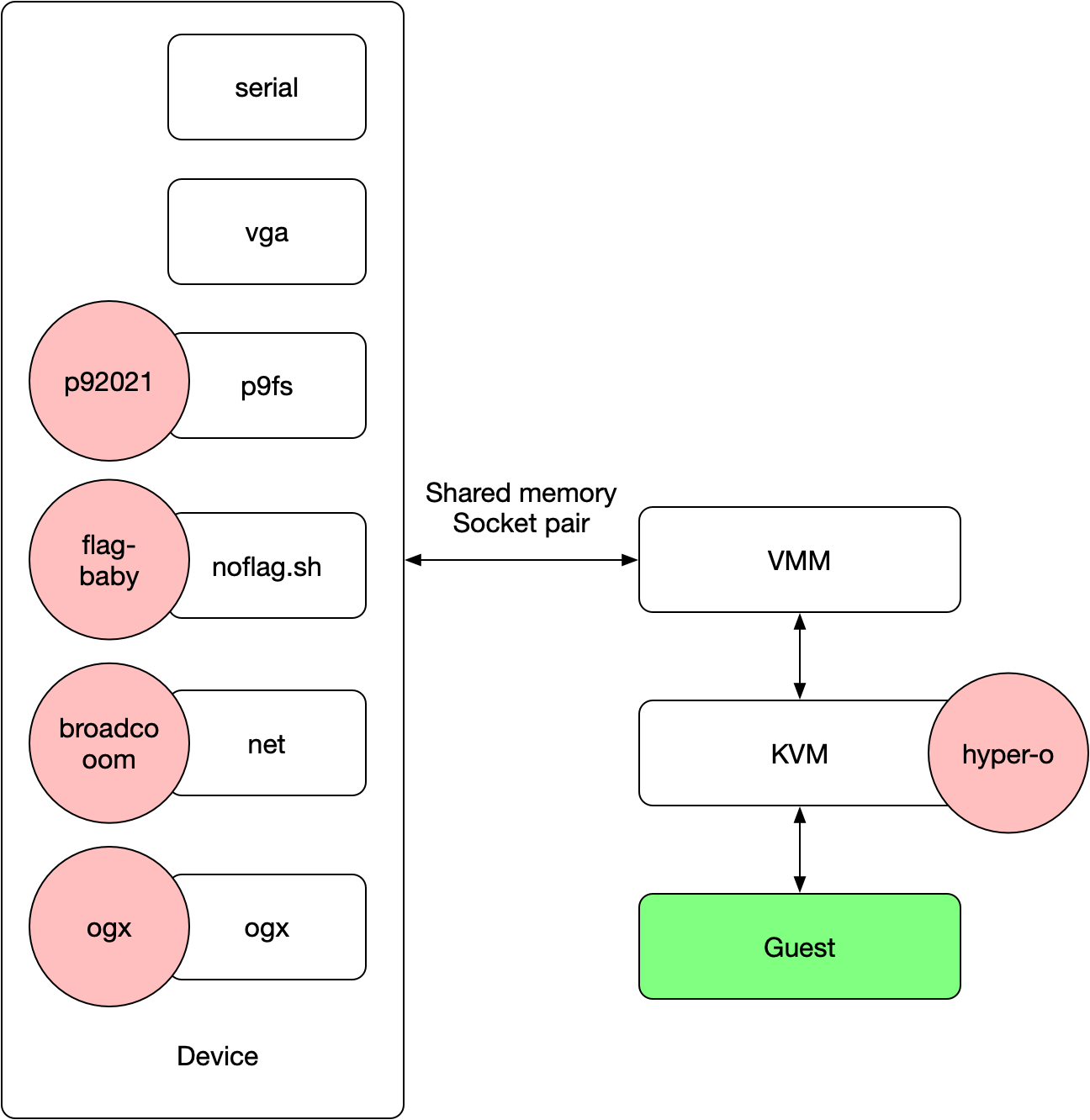
绿色的是用户可以控制的输入,即 guest 里的镜像,可以通过 port io / mmio 等于 hypervisor (vmm)交互,这里的 vmm 并非攻击的目标所以给了符号,方便队伍理解它虚拟化的工作机制。每个设备会单独起一个进程去处理,vmm 会为他们设置通信的 socketpair 以及 shared memory,将 guest 的 io 请求转发给他们。flag-baby / p92021 / ogx / broadcooom 都是实现了一个有漏洞的设备,而 hyper-o 则是实现了类似 kvm 的功能,编写了一个有问题的 kernel module,需要通过 guest 去 exploit.
flag-baby 是一个非常简单的用 shell 实现的设备,类似于一个示例,绕过里面的检查即可读取到 flag. 但这个题的交互不太容易,首先需要从实模式开始(即 BIOS 加载完 MBR 跳转过去的第一条指令)给 hypervisor 发送 io 请求来发送数据,实模式能做的事情比较有限也不利于编写更多的功能,需要切换到保护模式。感谢清华大学操作系统课 ucore lab1,让我们可以比较快的作出镜像;然而由于 MBR 的空间限制仅能够写 510 字节的代码,如果实现更多的功能,还另需读磁盘的功能;最后,用户直接访问到的是 web 界面,需要自动化上传镜像,从 serial / vga 读取结果,也有一定的工作量。好在相同架构的题有 5 个,所以写这些工具还是值得的。
8.7 白天时间一部分同学回去休息了,f1yyy,explorer, M4x, nan chen, WangDuo 等人继续分析 p92021,刚起来的生力军则开始分析接下来会出的 ogx 和 broadcooom. p92021 实现的是一个类似 9pfs 的共享文件系统,众人一开始猜测是个目录穿越什么的,也找了一个疑似的地方,结果后来被证明是假洞。不过 f1yyy 真不愧是 UAF 小能手,3:00pm 的时候又找到了一个 UAF,众人于是开始了艰难的风水和占位尝试。
由于调试不太方便,每次需要在 binary 中 patch 一个死循环来等待 attach 很麻烦,我写了一个 python 脚本模拟 vmm 与设备 process 交互的过程。随后 4:00pm 左右回酒店睡了一会,大概 9:00pm 左右回到了现场,此时 M4x, nan chen, WangDuo 等人已经完成了占位过程,但由于被占位的对象中有 string 的指针,在没有 leak 地址的情况下不好伪造,一时陷入了僵局。我考虑了一下 patch 方法,决定直接干掉漏洞点处的 delete 调用,如果能通过检查应该就没什么问题了,传统艺能之 nop free。
Day 2:勾心斗角
8.8 0:45am,主办方在赛前的 captain meeting 上说接下来会放出一个 KoH,ogx,之后是 broadcooom.
万事俱备,只欠exp
Riatre 在 8.7 大部分时间都在为 ooows 做准备,包括编写交互的脚本,准备防重放的工具等等,直到 8.7 很晚的时候才开始看题。而此时 M4x 已经想到可以使用固定地址的 shared memory 来伪造对象,从而伪造文件打开的路径读取 flag,最终还是能够达到目录穿越的效果。但众人很快又陷入了另一重困境之中——无法把 flag 的数据发送出来,原来这之后还有一个大坑,就是需要实现一遍 virtio 的交互过程…… 开赛时仍没有成型的 exploit,riatre 预测说我们开赛要被暴打。
1:00am 比赛开始,10 分钟后,StarBugs 就打出了 p92021 的一血,不过可能是没有自动化的缘故,每轮打的队伍都是零零散散的。之后终于自动化好了,发现仅有我们和 Katzebin 成功防守,也没有其他队进行攻击。整体状况比预想的要好,根据大家防守的情况看,甚至大部分队伍连洞都没有找到。PPP 在这道题上罕见地发挥失常,攻击端和防守端都没有建树,而 Katzebin 则趁机依靠防守的优势反超 PPP 登顶。
1:30am 放出了 ooows-ogx,我和 explorer 接替了白天 cxm,ziiiro 等人的工作继续分析。
3:00am 放出了新的 KoH —— www,刚刚睡下的 KoH 手们被再次唤醒。这是个可以互相在对方的 wall 上涂鸦的服务,如果涂鸦没被举报则获得分数,自己则需要隐藏真实的 IP 以免被别人举报扣分。在整个网络环境中,还有一些存在弱密码可以当做跳板机的 IP. 于是 web 手们来了精神,纷纷开始了内网扫描……
Patch-by-one,补不住的 ogx
ogx 是一个类似 SGX 的设备,可以输入一段 shellcode 并在隔离的环境中运行,这里使用的主要是 MPK 进行的内存访问隔离,题目中有若干个 enclave 可供上传代码。其中 ogx_enclave_flag.bin 作为初始的代码被加载到 enclave 0 中执行,flag 也被读入到 enclave 0 的内存中。它的逻辑非常简单,就是不断地读取 flag 地址+0x1000 位置的内存并与 0 比较,如果是 0 则 sleep 10s,否则继续循环。从这个场景来看,应该是一个较为明显的 cpu 漏洞的利用,需要我们从隔离的其他 enclave 中将 envclave 0 里的 flag 数据偷出来。比较奇特的是本题 patch 的文件正是这个 ogx_enclave_flag.bin,而且 patch 字节数的限制是 1 byte.
Riatre 提醒我们研读了一下 cacheout attack,但众人仍不得要领。
3:50am 左右我们的 p92021 exploit 终于 work 了,而且是防重放的实现,所以直接开始打正常的 port. 那么请问此时正在打 stealth port 的 StarBugs 会采取什么策略呢?
4:30am Katzebin 同样开始打 p92021,随后 StarBugs 和 Katzebin 都切换到了非 stealth port,紧接着其他队伍开始了重放。这样看来我们实现了很久的防重放 exploit 价值就没有那么大了,相当可惜。但本题总体表现还是非常不错的,在众队伍都可以打的情况下,收获了很多防御分数。
5:00am ooows-broadcooom 放出。
5:54am StarBugs 率先打满了 ooows-p92021 600 个 flag,题目下线。由于他们打的是 stealth port,所以即使比我们先打了 30 个 tick,攻击分只有 421 分,而没打过 stealth port 的我们也有 343 分的攻击分。
6:19am 左右,StarBugs 一血了 ogx,我们尝试 patch 了好几个地方,包括偏移、sleep 的时间等,似乎都没有完全防御住。随后 Katzebin 也开始了攻击,神奇的是一血的 StarBugs 竟然也没有补住这题。之后从流量中看,题目出现了 unintended 解法,由于 enclave 内部没有限制 syscall,所以直接 open / read / write 外部的 flag 文件即可,所以根本就不可能补住。
11:00am 第2个 round 结束,前4名变成了 Katzebin, PPP, StarBugs 和我们,主办方在 captain meeting 上说过一会将在 discord 上发出明天的两个新题 ooows-hyper-o 和 shooow-your-shell (KoH). 这样看来非常奇怪的 cooorling 将不会出现了。
除此之外,主办方还宣布了这是他们最后一届举办 Defcon ctf 的消息,一直以来总是被人吐槽的 OOO 真的要 “下课” 了,一时竟还有些不舍(xxxxx综合症么)是怎么回事。
马拉松式的逆向
我在 8:00am 左右跑到公司的沙发上躺了,直到快中午 12 点才起来和 f1yyy、explorer 等人开始分析 broadcooom. 这个题目从 8.7 晚上的时候就已经有同学开始在 work 了,但直到现在仍然还有很多逻辑未能弄清,需要一点点逆向。主 binary net 模拟了一个网卡设备,同时在处理的时候还使用了自己实现的一套 VM,实际的处理逻辑是位于 net-firmware 固件中,同时需要 patch 的也是这个固件文件。结合大爷的 idb 以及 afang5472 编写的初步 disassembler,我们逐渐理清了从 virtio 进来的网络数据包处理到发送给 MQTT 后端消息队列的数据流向,并对 net-firmware 里的处理逻辑有了基本的认识。
大约 4:00pm,我转向了 hyper-o,这道将在最后放出的 ooows 系列题目是一个 kvm 类似的内核模块,使用 vmx 指令来创建 VM,并读入 shellcode 执行。Discord 上放出的 hyper-o.ko 文件已经与之前泄露出的版本有很大的不同,去掉了一些功能,只留下了基本的映射内存,执行等,IO 部分的处理也简化了。外层则是一个简单的 vmm,直接从 stdin 输入 shellcode,主办方说这只是个临时的版本,正式开赛后会换成新的,但 hyper-o.ko 不会变。
比较蛋疼的是我本地老旧的 Ubuntu 16.04 似乎无法在应用了 kvm 的 qemu 里使用 vmx 指令,其他一些队员也出现了这种情况,可能与 kvm 和 qemu 的实现有一些关系。
8:20pm,远程支援的 equation314 在 hyper-o.ko 中找到了漏洞,可以通过操作 guest 内存来更改 EPT Pointer,从而伪造 EPT 页表任意读写 Host 的地址空间。大概 10:00pm 的样子,broadcooom 那边也找到了一个可以越界写改掉 firmware 代码的 bug,正在紧锣密鼓地研究如何触发以及编写 vm 代码的 shellcode.
然而,最后冲刺的 round 已近在咫尺。
Day 3:濒临绝境
3 字节的 shellcode
1:30am 最后一个 round 开始,我们的 KoH 选手顿时活跃起来,投入到 shooow-your-shell 的博弈中。
这又是一个编写 shellcode 的 KoH 游戏(为什么要说又?),需要编写一段读取 /secret 文件内容并输出的 shellcode,在给定的 3 个架构 x86_64, aarch64 和 riscv64 任意一个上成功即可。如果你的 shellcode 比别人长度短,或者使用的字符集合比别人小,则可以成为 king of the hill,同时上一段 shellcode 中没有被使用的字符(即 set(previous_shellcode) - set(shellcode))将被禁掉。
当一支队伍连续 900s 霸榜后,这次提交被标记为 winner,游戏将被重置。新的游戏将从之前所有的 winner 提交中随机抽取一个字符集作为禁止的字符集。基于这个设定,我们优化的目标并非只有将 shellcode 缩到最短或者字符集最小,还需要考虑对手的策略,可以故意提交一些使用字符比较多的 shellcode 以禁掉关键字节(例如 syscall)。
根据我之前参加 seccon (最早采用 King Of the Hill 赛制的比赛之一)的经验,很多时候都可以利用 shellcode 的运行环境获得更多的能力。例如本题的 shellcode 是使用 qemu user mode 启动,并在一个静态链接了 libc 的 binary wrapper 中被读入,然后直接跳过去执行的。这就意味着 shellcode 执行时可以利用静态链接的 libc 代码,使用 rop 的方式去完成功能。afang5472 利用 add / pop / ret 构造出了字符集仅为 3 的 shellcode,作为杀手锏。KoH 小组的其他成员编写了搜索的脚本,用于在有限字符集中搜索可能的解,同时思考了很多奇葩战术策略。
不得不说每次 KoH 都能整出点新花样(事故),之后的比赛中这题状况频出,但由于当时 bin 组的成员正为 2 个老大难的 challenge 焦头烂额,所以对玩的不亦乐乎的 KoH 题目并未关注过多。具体可以参考 StarBugs 这位老哥的回顾 https://github.com/qxxxb/ctf/tree/master/2021/def_con_finals.
终端噩梦
与此同时,broadcooom 和 hyper-o 的进展并不顺利。
最后一天的比赛照惯例隐藏积分榜,每个 tick 的时间缩短为 2.5min,这让我们难以获知自己的 patch 是否奏效了,只能从流量中大概搜索一下。开赛后马上 StarBugs 就一血了 hyper-o,但他们打的是 stealth port,没有流量可以分析。
Riatre 一上来传了一个 broadcooom 的 patch,被判定 SLA_FAILED 没有通过,过了一段时间再传一个同样了就 ACCEPTED 了,非常谜。
hyper-o 这边,我基本已经理清了整个利用的链路,然而一开始就写好的 bootloader 却失效了,cbmixx 尝试调了很长时间,发现似乎是 lgdt 指令没能执行成功,无法切换到保护模式,后面的利用就没法进行了。
2:30am 左右我发现已经有攻击流量了(其实已经有好几个 tick 有攻击流量了,没盯紧),并从其中找出了一段 payload,M4x 和 nan chen 测试后发现可以从最终寄存器的值中提取出 flag,遂开始准备重放。然而等到重放将要完成时,主办方宣布 hyper-o 题目部署更新,回到了之前 ooows 的界面形态,这样之前的 exploit 就不太能用了,还是得输出到 VGA.
2:43am Katzebin 一血了 broadcooom.
4:56am StarBugs 又再次一血了新的 hyper-o.
我们仔细分析了之前 hyper-o 的流量,发现里面有很多的 \x16 字符,原来是因为在终端里输入需要转义的缘故,而 payload 中正好含有 \x16 于是就被吃掉了,欲哭无泪。
5:30am,比赛结束,我们这个 round 的攻击分为 0,防御分未知,表现非常差,大家都认为这下要跪了。
终章:峰回路转
比赛一结束已经是周一的凌晨了,队内很多打工人收拾收拾就准备去上班,我则请了一天假,上午在酒店休息了一下等待结果。
意外的排名
最终排名如下
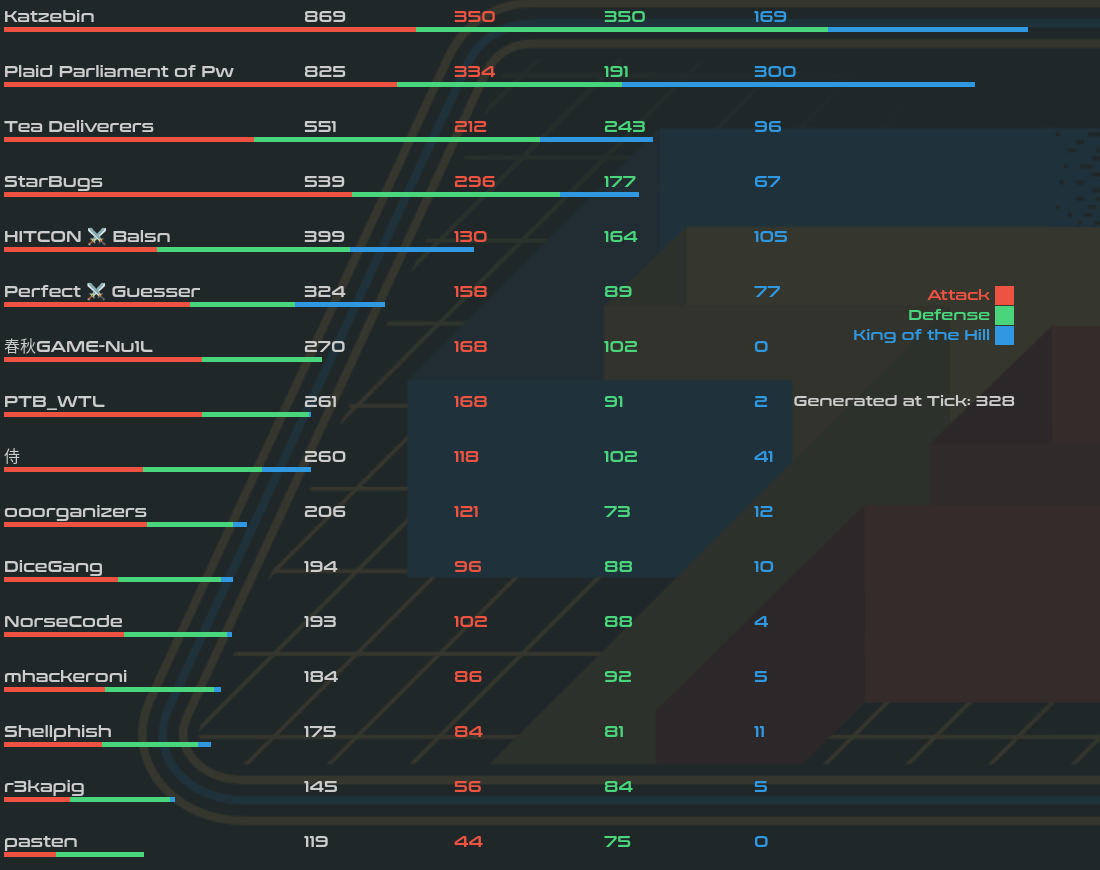
居然最后还反超了 StarBugs 来到了第 3 着实是令人感到意外,似乎是他们的 broadcooom 没有防住导致的(这题防御需要写 vm 的代码,并不容易),因为攻击分相对来说比较卷,总分上体现的没有防御分那么重要。
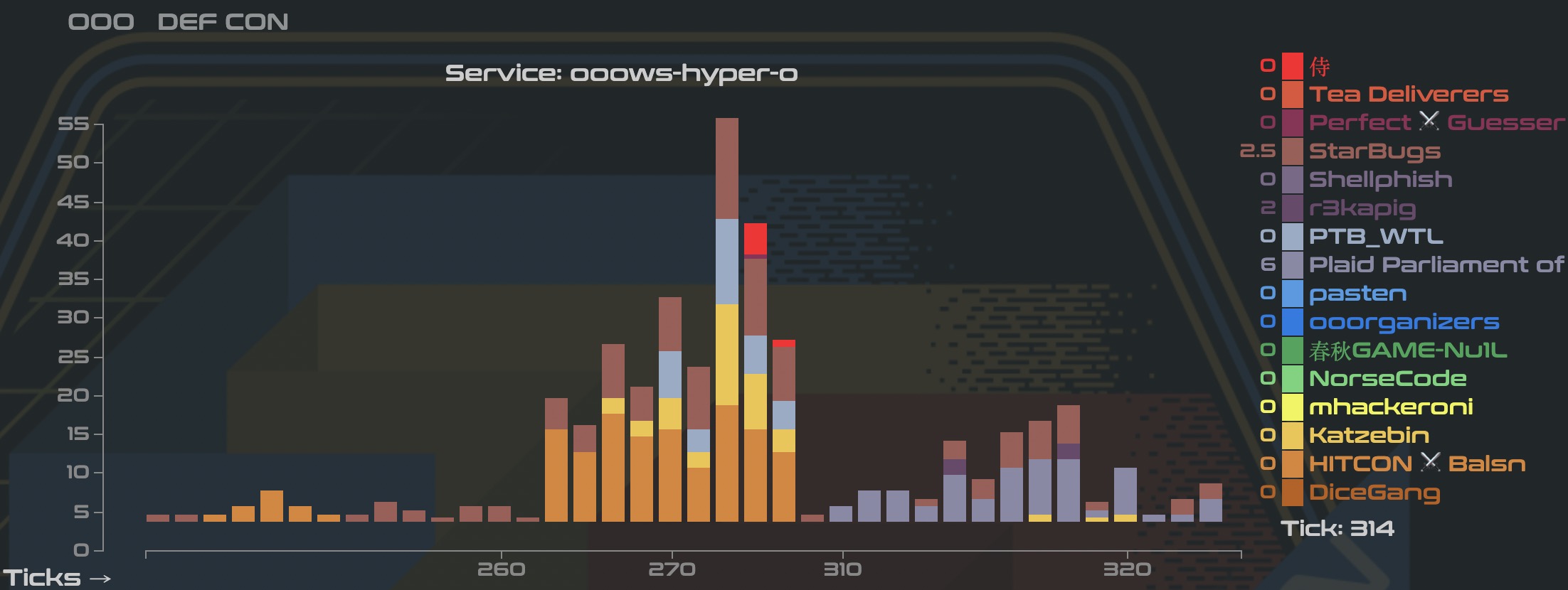
从事后 service 的统计来看(https://scoreboard.ooo/services.html),我们的 broadcooom 防御立了大功,而 hyper-o 却没有补住,看来还有 bug 是我们没找到的。之前发现的流量应该是 HITCON 的,他们没有打 stealth port. 不过本题大家都没有补住,所有队伍的防御分都比较相近。
尘归尘,土归土
总结一下整场比赛下来的感受
- 感觉仍然还是现场面对面交流会比较及时一点,大家基本没有通过合作文档更新进度的习惯,很多时候都是口头沟通,相对比较高效。缺点是没有记录下来的东西可以看,导致之后的同学就只能再给他讲一遍,比较浪费时间。
- 赛前的准备有些还是很有用的,譬如可视化的平台和自动攻击平台;但有些则完全没有起到作用,譬如很多协作规范,很多事情真到了比赛的时候就是怎么方便怎么来了。
- Patch 小组基本完成了任务,至少从防御分上看,我们位居第 2,在每个题目发现漏洞后都能及时跟进修复,这是比去年有所进步的地方,当然也是因为跟我们漏洞发现的比较快,题目里漏洞少。
- 这次的题目质量还是不错的,但由于这样那样的 bug 导致体验很差,没法安心竞技。
- Defcon 风格的题目,逆向工作量和利用工作量跟国内比赛都不是一个量级,甚至投入 7、8 个人轮班,连续 work 20 个小时都不一定能写出利用,这其中当然也有经验和基础知识的不足因素存在(例如 virtio,设备交互等等),不过分工协作上还是存在一定的问题。
- StarBugs 确实在攻击力上无人能出其右,然而他们仅拿到了第 4,据说是由于协作混乱所致,看来他们没有专人负责 patch。而且攻击上基本都是无脑打 stealth port,也不考虑怎么防止重放,一血的优势不怎么明显。这也说明了在这种赛制下,光写利用厉害还是不够的,在策略上还是得考虑更多。
关于主办方 OOO,我们能明显看到这几年他们在改进赛制和题目质量上的努力(虽然还是经常出包),总体来看还是在往好的方向发展的。不知道下届主办方会交给谁,有人说 PPP 比较合适,大家调侃那就变成亚洲 CTF 了。确实亚洲队伍的强势在这几年特别显著,毕竟大家的重视程度不同。不管怎么说,还是希望 DEFCON CTF 这个曾经众多 CTF 选手的初心能够一直高质量地办下去,也希望更多的国内队伍能闯入决赛吧。
事后:也写回忆录
下面是一些大佬们的回忆,可以从不同视角来了解这次比赛
- https://iromise.com/2021/08/11/DEF-CON-CTF-29-Final/ (Chinese)
- https://dttw.tech/posts/ByGpq5bgt
- https://blog.iret.xyz/article.aspx/defcon_devops_recooord (Chinese)
- https://elnx.github.io/def-con-ctf-2021 (Chinese)
ooows 的官方 github repo
]]>