
Linux Kernel Heap 101 —— Buddy & Slab
随着大家对glibc内存管理机制研究的深入,越来越多的heap master涌现出来,导致在pwn领域你不对 2.23~2.29 每个版本的glibc了若指掌都不好意思说自己玩过堆。这也使得国内很多CTF的堆题更多的是流于形式和trick比拼,内卷严重。因此,我的兴趣逐渐转移到了更加贴近真实环境的kernel和虚拟化上。于是,内核的heap成为了新的战场……
前言
工欲善其事,必先读源码。每每有人问我如何搞好glibc的堆,我都让他们去下一份glibc的源码,打开 malloc.c 好好看一遍。尽管本着搞CTF要把知识吃透的原则,读一遍内核堆实现的源码才是修炼内功的唯一途径。不过从目前CTF的题目来看,也duck不必,一方面赛棍们在这块的研究并没有太过深入,另一方面相关资料还是很多的,找两篇blog看一下就能明白原理了(譬如本文). 至于以后CTFer会不会把内核堆玩成像glibc一样“5年堆题,3年模拟”,只有期待下一个 angelboy 的出现了。
对于内核堆来说,只需要了解分配大内存的Buddy System和分配小内存的Slab(Linux针对原始的Slab算法进行了优化,开发了新的SLUB算法,该算法是内核堆内存分配的默认算法,下文不特别说明介绍的就是SLUB算法)。其实从国内这些年出的题来看,懂一点Slab就可以走遍天下都不怕了。不过前阵子的Defcon Quals中的kernel题目就牵涉到了buddy的一些内容,这使得我有了系统梳理一下的动力。鉴于网上介绍原理的资料确实相当多,我就精简一下内容,着重讲解一下基本的性质、相关API以及在CTF中的应用。
Buddy System
算法原理
伙伴系统,专门用来分配以页为单位的大内存,且分配的内存大小必须是2的整数次幂。这里的幂次叫做 order,例如一页的大小是4K,order为1的块就是 2^1 * 4K = 8K。每次分配时都寻找对应order的块,如果没有,就将order更高的块分裂为2个order低的块。释放时,如果两个order低的块是分裂出来的,就将他们合并为更高order的块。
我们用wiki中的例子就可以很好地说明了。
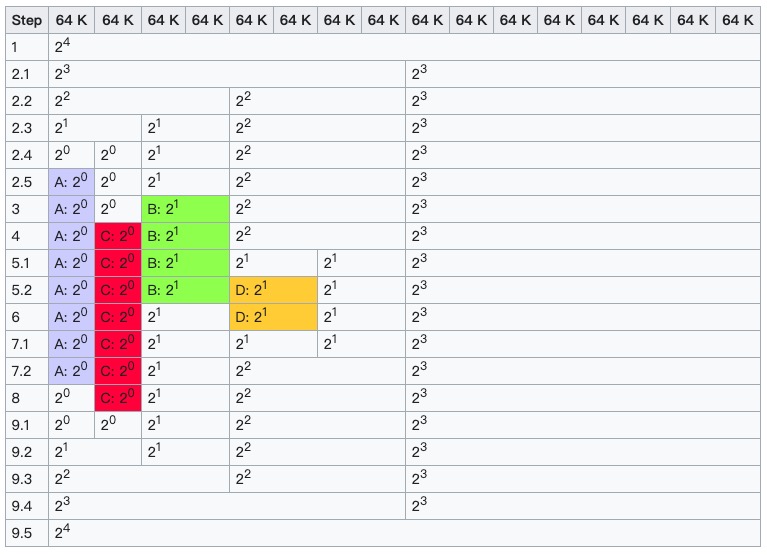
这个例子中,分配的最小单位是64K,初始时的最大块order=4. 依次进行下面的操作
- 初始状态
- 分配块A 34K, order=0.
- 没有order为0的块,切分order=4的块为2个order=3的块.
- 仍然没有order=0的块,再切分order=3的块.
- 仍然没有order=0的块,再切分order=2的块.
- 仍然没有order=0的块,再切分order=1的块.
- 将order=0的块返回.
- 分配块B 66K, order=1. 已经有了,直接返回.
- 分配块C 35K, order=0. 也已经有了,直接返回.
- 分配块D 67K, order=1. 切分一个order=2的块,返回.
- 块B释放.
- 块D释放,因为与其后面的order=1的块是第5步分裂得来的,再将其合并为order=2的块.
- 块A释放.
- 块C释放,依次合并.
注意这里合并的时候,被合并的邻居得是之前分裂出来的伙伴(Buddy),这也是该算法的由来.
Linux实现
在Linux中,使用buddy system分配的底层API主要有 get_free_pages 和 alloc_pages,传入的参数都是order,还有一些flag位.
值得注意的是这样分配得到的虚拟地址和物理地址都是连续的,返回的地址可以使用 virts_to_phys 或者 __pa 宏转换为物理地址,实际操作也就是加上了一个偏移而已。
可以通过 /proc/buddyinfo 和 /proc/pagetypeinfo 来查看相关的情况.
Slab分配器
基本原理
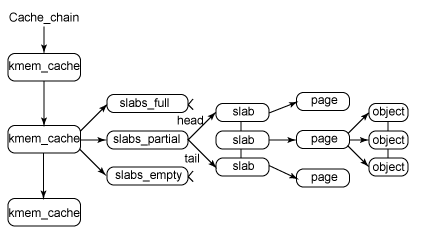
这张图可以说是介绍slab的文章中出现频次最高的了,我们只要记住,kmem_cache是类似于glibc arena的结构,每个kmem_cache由若干个slab构成,每个slab由一个或多个连续的页组成。kmem_cache有一个重要的性质,就是其中所有的object大小都是相同的(准确的说是分配块的大小都相同).
我们借助linux的 /proc/slabinfo 来说明,也可以使用 slabtop 工具来查看slab分配的状态。
1 | # cat /proc/slabinfo |
这个文件列出了目前所有的 kmem_cache,第一列是每个mem_cache的名字,我们拿 kmalloc-64 来做说明
- active_objs: 目前使用中的object数量,一共分配出了40682个objects.
- num_objs: 总共能够分配的object数量,这里最大是47808个.
- objsize: 每个object的大小,这里是64 bytes.
- objperslab: 每个slab可以有多少个object,这里是64个.
- pagesperslab: 每个slab对应几个page,这里是1个.
所以我们可以看出,kmalloc-64 这个mem_cache,每个slab有1个page也就是4K,每个对象是64B,所以每个slab能容纳的对象是 4K / 64B = 64 个. 如果分配了object数量超过了64个,就需要从别的slab分配,如果分配的对象超过了47808个,就需要申请新的slab,也就是向buddy system申请新的内存页.
相关API
Linux中的一些常用内核API.
1 | struct kmem_cache * kmem_cache_create ( const char *name, |
创建mem_cache,需要指定name和size.
1 | void * kmem_cache_alloc (struct kmem_cache * cachep, gfp_t flags); |
在mem_cache中分配object,这里不需要指定size因为在创建时就已经指定好了.
1 | void kmem_cache_free (struct kmem_cache * cachep, void * objp); |
在mem_cache中释放object.
1 | void * kmalloc (size_t size, gfp_t flags); |
分配size大小的对象,会在 kmalloc-xxx 这些特殊的mem_cache里找到一个适合的进行分配.
如果size超过了最大的kmalloc mem_cache,比如上面那个slabinfo里最大的是 kmalloc-8192,如果分配超过8192 bytes的话,还是会调用底层API直接向buddy申请内存.
1 | void kfree (const void * objp); |
释放对象 objp ,实际会先找到其所在的page,然后读取page结构中指向其所属slab的指针,进而放到对应的freelist(单链表)中,并将指向freelist中下一块的fd指针写到块的头部.
CTF中的利用
最为大家所熟知的利用就是改fd了,因为freelist是单链表结构,且没有检查,类似于glibc中的tcache,基本就是指哪打哪的节奏。
基于freelist LIFO的性质UAF漏洞可以用相同大小的结构占位的方式来改一些指针,这里不再赘述。
这次Defcon Quals中的keml,是在 get_free_pages 分配的堆块上产生的溢出。看似使用buddy分配的内存溢出之后覆盖不到什么对象,实则不然,当耗尽某个mem_cache后,其会向buddy申请新的内存页作为slab,这就有机会将slab的内存页放置到有漏洞堆块的后方,改到slab中的内容了。而且由于buddy分配内存连续的性质,不同mem_cache的slab完全有可能会交错在一起,给内核堆风水带来了新的可能性。有兴趣的读者可以尝试解一下该题(文末引用中有链接).
总结
内核堆上的利用相对来说较为简洁,套路不多,这得益于内核中数量繁多的对象和slab分配器的简单实现。
相较于glibc众多 house of 的层出不穷,内核中只要控制了fd,直接去改掉 modprobe_path 就能够以root权限执行命令,简单粗暴。
不知道Linux kernel会不会考虑针对堆管理增加一些防护,也许内核堆攻防博弈的时代即将到来 :)