
Linux Kernel Userfaultfd 内部机制探究
在最近的 CTF Kernel Pwn 中,使用内核的 userfaultfd 机制来进行稳定 race 频率越来越高了,而我之前在做题时大都按照 man page 中的例子和一些 API 文档来猜测其用法。在 SECCON 2020 结束后,还是想从源码层面研究一下其内部机制是怎样的,这样可以在之后的应用中少踩一些坑。
引子
在 SECCON 2020 的 kstack 这道 kernel pwn 里,使用了 userfaultfd + setxattr 的所谓“堆喷射”技术,也就是这篇 blog 里介绍的技术,个人觉得使用 heap spray 的说法不是特别准确,在本题中这种技术就是用于在 double free 之后来完成对 UAF 对象的占位篡改,并不仅仅可以用于做堆喷。
说回正题 userfaultfd,这是 kernel 中提供的一种特殊的处理 page fault 的机制,能够让用户态程序自行处理自己的 page fault.
它的调用方式是通过一个 userfaultfd 的 syscall 新建一个 fd,然后用 ioctl 等 syscall 来调用相关的API. 该机制的初衷是为了方便虚拟机的 live migration,其功能还处在不断改进和发展中,文档和资料都不是很多。
这里我主要以 v5.9 内核源码为基础,结合2个 man page(参考文末的链接) 来进行说明。
UserfaultFD 的工作流程和用法
文末的引用中有一个讲得比较好的 slides,里面有张图可以很好地说明其工作流程
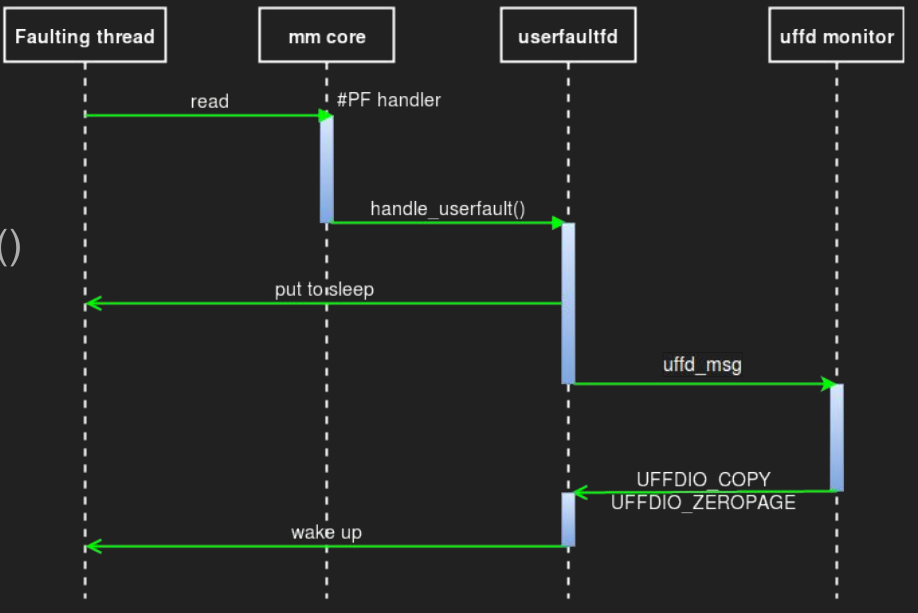
左侧的 Faulting thread,mm core,userfaultfd 是属于同一个(内核)线程,右边的 uffd monitor 是属于另一(内核)线程,它们在用户态应该表现为共享地址空间的2个线程。
在开始时,faulting 线程读取了一块未分配物理页的内存,触发了page fault,此时进到内核中进行处理,内核调用了 handle_userfault 交给 userfaultfd 相关的代码进行处理,此时该线程将被挂起进入阻塞状态。同时一个待处理的消息 uffd_msg 结构通过该 fd 发送到了另一个 monitor 线程,该线程可以调用相关 API 进行处理 ( UFFDIO_COPY 或 UFFDIO_ZEROPAGE)并告知内核唤醒 faulting 线程。
从这个例子中我们能看出这里面涉及到2个线程之间的交互,我们也不能免俗地要介绍一下具体用法,阅读 userfaultfd man page 里给出的例子,里面大概分为几步:
1. 分配一个 userfault fd 并检查 API
由于 glibc 没有对应的 syscall wrapper,直接使用 syscall 函数分配。
1 | /* Create and enable userfaultfd object */ |
2. 注册需要进行 userfault 的内存区域
1 | /* Register the memory range of the mapping we just created for |
3. 创建 monitor 线程,(子线程)监听 fd 的事件
在一个 for 循环中,不断使用 pool 来等待这个 fd ,然后读取一个 msg,这里读取的 msg 就是 uffd_msg 结构。
1 | for (;;) { |
4. 主线程触发指定区域的 page fault
读一下该区域的内存即可
5. (子线程)处理 fault
调用 UFFDIO_COPY 为新映射的页提供数据,并唤醒主线程,子线程自身会进入到下一轮循环中继续 poll 等待输入。
1 | /* Copy the page pointed to by 'page' into the faulting |
UserfaultFD 的相关源码
我最感兴趣的有几个地方,一是内核如何标记需要user fault处理的内存页的,二是当 page fault 发生时内核如何交给用户态处理,三是那个页映射是何时又是怎么恢复的。
涉及 userfaultfd 处理的主要有以下几个文件
fs/userfaultfd.c:主要逻辑都在该文件中mm/userfaultfd.c:一些跟页表相关的底层函数mm/memory.c:通用的处理 page fault 的代码mm/mremap.c/mm/mmap.c:处理 mremap 和 mmap 的代码,本文暂时不研究
既然是一个 fd 那么就应该有实现文件操作的接口,理所当然的我们在 fs/userfaultfd.c 中找到了其实现
1 | static const struct file_operations userfaultfd_fops = { |
其中主要的控制接口就是 ioctl,实现了若干个 cmd
1 | switch(cmd) { |
注册fault area
当我们调用 UFFDIO_REGISTER 时,内核进入到 userfaultfd_register 函数,首先检查对应 vma 的合法性
1 | ret = validate_range(mm, &uffdio_register.range.start, |
这里要求地址得在用户态的范围内,而且要在 task 的 mm 结构中能找到,换言之,这应该是已经分配了虚拟地址的 page.
那么如果在这样的页上发生了 page fault,这个 page 应该是 已经mmap映射,但还未分配实际物理内存 的 page.
回想 man page 中的例子,在 mmap 成功后立即进行了 register 操作,没有对该区域进行过读写。
这也告诉我们,想对没有映射虚拟地址的 page 进行 register 是不行的。
在这之后,内核将对应的 vma 添加一个flag(VM_UFFD_MISSING 或 VM_UFFD_WP)
1 | vm_flags = 0; |
代码中还包括其他对 vma 的检查处理,这里不再赘述。
发生 page fault 时的处理
从前面的图中我们知道内核处理 userfault 的核心函数是 handle_userfault,当发生 page fault 时,在内核中的调用链如下(x86架构)
exc_page_fault->handle_page_fault(v5.9中 page fault 的入口点) /page_fault->do_page_fault(低版本的入口点),它们位于arch/x86/mm/fault.cdo_user_addr_faulthandle_mm_fault(mm/memory.c)handle_pte_faultdo_anonymous_page(这里看到 userfault 仅能处理 anonymous page,4.11之后还能支持 hugetlbfs 和共享内存)handle_userfault(fs/userfaultfd.c)
在 handle_userfault 中,默认的返回是 VM_FAULT_SIGBUS,如果该 fault 不是第二次发生 (有 FAULT_FLAG_ALLOW_RETRY 的标志位),则返回值被改为 VM_FAULT_RETRY
1 | vm_fault_t ret = VM_FAULT_SIGBUS; |
在这之后,内核将该 fault 线程挂起,将这个事件加入到 ctx->fault_pending_wqh 这个 wait queue 中,这会使得 userfaultfd_poll 和 userfaultfd_read 返回给 monitor 线程对应的消息结构,并等待处理。在处理完成后,再将线程状态设为 TASK_RUNNING 并返回。
UFFDIO_COPY
该API用于向以分配的 page 中预先写入数据,这个写入操作位于原 fault 线程读写数据之前。
在 userfaultfd_copy 中,会调用 mcopy_atomic (mm/userfaultfd.c) 分配物理内存,并将用户提供的数据 copy 过去,最后调用 wake_userfault 唤醒 fault 线程。
UFFDIO_WAKE
直接调用 wake_userfault 唤醒 fault 线程。
需要注意的几点
这里主要讨论几种特殊情况,都是我在做题过程中进行的一些奇怪的尝试。
不处理直接 UFFDIO_WAKE 会怎样
第一次page fault会返回 VM_FAULT_RETRY, 之后就看具体内核的处理方式了。
有的版本内核 VM_FAULT_RETRY 之后会清除 FAULT_FLAG_ALLOW_RETRY 标志位,回到用户态之后再次触发 page fault,此时 handle_userfault 会返回 VM_FAULT_SIGBUS 导致进程收到 SIGBUS 信号终止。
而不巧的是我选择的目标 v5.9 版本的内核是直接在 do_user_addr_fault 中直接 goto 到之前的位置重新处理,但没有清除这一标志位,这就直接导致了一个死循环。
UFFDIO_UNREGISTER 再 UFFDIO_WAKE 会怎样
因为在 retry 时,该 vma 上用于 userfault 的标志位已经清除,所以将由 kernel 自行处理。
在 monitor 线程中访问 faulting 的 page 会怎样
Obviously, 会产生死循环。
小结
对于 kernel pwn 来说,userfaultfd 可以非常有效地控制 race 的顺序,通过与 setxattr syscall 的配合甚至可以完成对(几乎)任意大小的内核对象进行占位,确实是当前内核选手必须要掌握的一项技术。而由于其代码迭代比较频繁,有一些诸如 UFFDIO_REGISTER_MODE_WP (写保护)的模式并非所有版本的内核都支持(当前的 man page 还声明尚未支持),还有对 shared memory, mmap/mremap 的处理也没有进一步讨论了。有兴趣的同学可以参考源码了解一下。
Reference
- https://man7.org/linux/man-pages/man2/userfaultfd.2.html
- https://man7.org/linux/man-pages/man2/ioctl_userfaultfd.2.html
- http://lastweek.io/notes/userfaultfd/
- https://www.slideshare.net/kerneltlv/userfaultfd-current-features-limitations-and-future-development
- https://www.kernel.org/doc/Documentation/vm/userfaultfd.txt
- https://elixir.bootlin.com/linux/v5.9/source/fs/userfaultfd.c